프로세스: OS가 만들어내는 환상의 기술
목차
Introduction
📌 시작하며
OSTEP 4장 "The Abstraction: The Process"를 읽다가, 작업 관리자를 한번 열어봤다.
프로세스가 300개 넘게 돌아가고 있었다. 내 노트북 CPU 코어는 8개인데.
8개로 300개를 어떻게 돌리고 있는 거지? 시분할이라는 건 알고 있었는데, 막상 숫자로 보니까 감이 안 왔다. 한 CPU가 동시에 37~38개의 프로세스를 담당하고 있다는 건데, 대체 어떻게 이게 자연스럽게 돌아가는 건지 궁금해졌다.
읽으면 읽을수록 질문이 꼬리를 물었다.
- OS는 왜 굳이 CPU가 여러 개인 것처럼 속여야 할까? 그냥 순서대로 실행하면 안 되나?
- 시분할이 성능을 낮춘다는데, 대체 얼마나 낮아지는 걸까? 체감할 수 있는 수준인가?
- CPU 작업 중에도 I/O를 할 수 있다길래 당연히 병렬로 돌아갈 줄 알았는데, 왜 I/O가 CPU를 기다리는 상황이 생기는 거지?
- 스택이랑 힙을 왜 굳이 나눈 걸까? 그냥 하나로 쓰면 안 되나?
이 글은 그 질문들을 하나씩 파헤쳐간 과정이다.
📌 이 글에서 다루는 것
프로세스 추상화의 본질을 이해하는 것이 목표다.
- 왜 가상화가 필요한가 - 환상의 근본 이유
- CPU 가상화의 원리 - 시분할과 성능의 trade-off
- 메모리 구조의 설계 - 적재 방식과 스택/힙 분리
- CPU와 I/O의 관계 - 병렬성의 본질
- 정책의 중요성 - 같은 메커니즘, 다른 결과
글 중간중간 OSTEP 공식 시뮬레이터로 직접 돌려본 결과도 함께 실었다. 정책 하나 바꾸는 것만으로 CPU 이용률이 54%에서 100%까지 달라진다길래, 진짜인지 확인해보고 싶었다.
시뮬레이터 구현 세부사항은 최소화하고, 왜 그런지에 집중한다.
📌 이 글에서 사용하는 실험에 대하여
이 글의 모든 실험 결과는 OSTEP에서 제공하는 교육용 시뮬레이터(process-run.py)를 기반으로 한다.
이 시뮬레이터는 실제 운영체제를 그대로 재현하는 것이 아니라, 프로세스 상태 전이와 스케줄링 정책 효과를 이해하기 위해 현실을 단순화한 모델이다.
따라서 본문의 수치들은 실제 OS 성능을 정밀하게 예측하기 위한 값이 아니라, 정책 차이가 어떤 방향으로, 왜 성능에 영향을 주는지 설명하기 위한 정성적·구조적 근거로 사용된다.
이 글의 목적은 "얼마나 빠른가"가 아니라, "왜 이런 차이가 발생하는가"를 이해하는 데 있다.
환상은 왜 필요한가
📌 프로세스란 무엇인가
프로세스(Process): 실행 중인 프로그램
정의는 단순하다.
디스크에 저장된 정적인 명령어 집합(프로그램)이 메모리에 올라가 실행되면 프로세스가 된다.
OS는 여기서 멈추지 않는다. 각 프로세스에게 전용 CPU가 있다는 환상을 제공한다.
실제로는 CPU 하나를 수백 개 프로세스가 나눠 쓰는데, 각 프로세스는 자신만 실행되고 있다고 착각한다.
📌 왜 이런 환상을 만드는가
처음엔 이게 좀 과하지 않나 싶었다. CPU를 여러 개인 척 속이는 게 왜 필요하지? 그냥 프로세스를 순서대로 돌리면 되는 거 아닌가?
환상이 없는 세계를 상상해봤더니 바로 이해가 됐다.
프로그래머가 "다른 프로그램이 언제 실행될지" 신경 써야 한다. "내 프로그램이 CPU를 언제 빼앗길지" 계산해야 하고, 멀티태스킹을 위해 프로그램마다 스케줄링 코드를 넣어야 한다.
환상이 있으면?
프로그래머는 "내 프로그램만" 생각하면 된다. CPU는 무한하다고 가정하고 코드를 작성한다. OS가 알아서 시간을 나눠준다.
프로그래밍이 단순해진다. 이것이 가상화의 핵심 가치다.
생각해보면 현대 프로그래머가 printf("Hello")만 쓰면 화면에 출력되는 것도 같은 맥락이다. 프로세스 추상화 덕분에 "다른 프로그램의 존재"를 무시하고 코딩할 수 있다. 그 뒤에서 OS가 얼마나 고생하고 있는지를 OSTEP을 읽으면서 알게 됐는데, 솔직히 좀 놀라웠다.
📌 환상을 만드는 재료
OS가 이 환상을 만들려면 무엇이 필요한가?
프로세스의 하드웨어 상태는 크게 세 가지로 구성된다.
- 메모리 - 프로그램 코드와 데이터가 저장된 곳
- 레지스터 - 현재 실행 상태를 담은 CPU 내부 저장소
- I/O 정보 - 열린 파일, 네트워크 소켓 등
이 중 가장 중요한 것은 메모리와 레지스터다.
메모리가 없으면 무엇을 실행하던 프로세스였는지 자체가 사라진다. 프로그램 코드, 데이터, 실행 가능한 명령어가 모두 메모리에 있으니까.
레지스터가 없으면 어디까지 실행했는지를 복구할 수 없다. Program Counter(PC), Stack Pointer(SP), 범용 레지스터들이 프로세스의 현재 상태를 담고 있다.
CPU 가상화: 하나가 여럿이 되는 마법
📌 시분할의 원리
CPU 하나로 여러 프로세스를 실행하는 방법은?
시분할(Time Sharing) - CPU 시간을 잘게 쪼개서 프로세스들에게 돌아가며 할당한다.
시간 →
P1 실행 | P2 실행 | P3 실행 | P1 실행 | P2 실행 | ...
10ms 10ms 10ms 10ms 10ms
각 프로세스는 10ms씩 실행되고, 다음 프로세스에게 CPU를 넘긴다. P1 입장에서는 "잠깐 멈췄다가 다시 실행된 것"일 뿐이다.
어떻게 멈춘 지점에서 다시 시작할 수 있는가?
문맥 교환(Context Switch) 시
- 현재 프로세스의 레지스터를 메모리에 저장
- 다음 프로세스의 레지스터를 메모리에서 복원
- 다음 프로세스로 점프
레지스터에 "어디까지 실행했는지"가 저장되어 있으므로, 복원만 하면 정확히 이어서 실행할 수 있다.
📌 성능 저하의 본질
"시분할 기법은 CPU를 공유하기 때문에, 각 프로세스의 성능은 낮아진다." - OSTEP
OSTEP에서 이 문장을 읽었을 때, "당연한 소리 아닌가?" 싶었다. CPU를 나눠 쓰니까 느려지는 거지 뭐.
근데 곰곰이 생각해보니, 왜 느려지는지를 정확히 설명하라고 하면 좀 막막했다. 단순히 "나눠 쓰니까"만으로는 부족하다.
세 가지 이유가 있다.
1. CPU 시간의 분할
- 프로세스 하나만 실행할 때: CPU 100% 사용.
- CPU 사용 프로세스 셋이 실행될 때: 각각 33% CPU 사용.
- 동일한 작업을 하는데 시간이 3배 걸린다.
여기까지는 직관적이다.
2. 문맥 교환 비용
이게 생각보다 만만치 않았다. 문맥 교환이 발생할 때마다 레지스터 저장/복원, 캐시 무효화, TLB(Translation Lookaside Buffer) 플러시, 파이프라인 stall이 뒤따른다. 이 오버헤드가 누적되면 실제 작업 시간이 더 줄어든다.
단순히 "시간을 나눠 쓴다"가 아니라, 나누는 행위 자체에도 비용이 든다는 점이 핵심이다.
(문맥 교환 비용이 실제로 얼마나 되는지는 Limited Direct Execution 챕터에서 다룰 예정이다.)
📌 메커니즘과 정책의 분리
OSTEP을 읽으면서 인상 깊었던 개념이 하나 있다.
- 메커니즘(Mechanism): 어떻게 할 것인가 (시분할, 문맥 교환)
- 정책(Policy): 언제 할 것인가 (어느 프로세스를 먼저 실행할까?)
처음엔 "그게 그거 아닌가?" 싶었다. 근데 같은 메커니즘(시분할)을 사용하더라도
- "I/O 요청 시 다른 프로세스로 전환한다" vs "전환하지 않는다"
- "I/O 완료 시 즉시 실행한다" vs "나중에 실행한다"
이런 정책 차이만으로 CPU 이용률이 54%에서 100%까지 달라진다는 걸 시뮬레이터로 확인하고 나서야 둘의 차이를 체감했다. 아래에서 직접 보여주겠다.
메모리: 프로세스가 사는 공간
📌 프로그램은 어떻게 프로세스가 되는가
프로그램을 실행하면 OS는 다음을 수행한다.
- 코드와 정적 데이터를 메모리에 적재
- 스택 공간 할당
- 힙 공간 할당
- I/O 초기화 (표준 입출력 등 - 이 과정에서 fd를 활용)
main()으로 점프
여기서 OSTEP을 읽으며 궁금했던 질문이 두 가지 있었다.
📌 왜 적재 방식이 바뀌었는가
코드와 정적 데이터를 메모리에 탑재하기 위해서 운영체제는 디스크의 해당 바이트를 읽어서 메모리의 어딘가에 저장한다. 초기 운영체제들은 프로그램 실행 전에 코드와 데이터를 모두 메모리에 탑재하였다. 현대의 운영체제들은 이 작업을 늦추었다. 즉, 프로그램을 실행하면서 코드나 데이터가 필요할 때 필요한 부분만 메모리에 탑재한다. - OSTEP
OSTEP에서 이 문단을 읽었을 때, "왜 바뀐 거지?"가 바로 떠올랐다. 전부 올리는 게 더 단순하고 확실한데, 굳이 복잡하게 필요한 것만 올리는 방식으로 전환한 이유가 뭘까.
- 초기 OS: 프로그램 전체를 메모리에 올림 (Eager Loading)
- 현대 OS: 필요한 부분만 올림 (Lazy Loading / Demand Paging)
| 방식 | 장점 | 단점 |
|---|---|---|
| Eager Loading | 실행 시작 후 빠름 | 시작이 느림, 메모리 낭비 |
| Lazy Loading | 시작이 빠름, 메모리 효율적 | Page Fault 발생 가능 |
현대 프로그램의 크기를 생각해보면 금방 납득이 됐다. 수백 MB ~ GB짜리 프로그램이 모든 코드를 다 쓰지도 않는데, 전부 메모리에 올린다고?
예를 들어, 크롬 브라우저를 실행할 때 "설정 페이지" 코드까지 미리 로딩할 필요가 없다. 사용자가 설정을 열 때 로딩해도 늦지 않다.
Lazy Loading은 시작 속도와 메모리 효율을 동시에 잡는다. Page Fault 처리 비용이 있지만, 전체적으로 이득이 크다.
(각 방식의 세부 동작 원리는 paging과 swapping을 이해해야 알 수 있다. 이후 포스팅에서 다룰 예정.)
📌 왜 스택과 힙을 나눴는가
이것도 OSTEP을 읽으면서 "왜 굳이?" 싶었던 부분이다. 그냥 메모리 하나에 다 넣으면 안 되나?
높은 주소
├─ Stack ↓ (아래로 성장)
│
│ (사용 가능 공간)
│
├─ Heap ↑ (위로 성장)
├─ Data (정적 데이터)
├─ Code (프로그램 코드)
낮은 주소
하나씩 따져보니 나누는 이유가 분명했다.
1. 생명주기가 다르다
- 스택은 함수 호출과 함께 자동으로 생성/소멸된다.
- 힙은 프로그래머가 명시적으로 할당/해제한다.
void foo() {
int local = 10; // 스택 - foo() 종료 시 자동 소멸
int* ptr = malloc(20); // 힙 - free() 호출까지 유지
free(ptr);
}
2. 크기 예측 가능성이 다르다
- 스택은 컴파일 타임에 크기를 결정할 수 있다.
- 힙은 런타임에만 크기를 알 수 있다.
연결 리스트, 동적 배열 같은 가변 크기 자료구조는 힙에서만 구현 가능하다.
3. 메모리 관리 효율이 다르다
- 스택은 LIFO 순서로 할당/해제하므로 단순하고 빠르다. 포인터 하나만 움직이면 할당/해제가 끝난다.
- 힙은 무작위 순서로 할당/해제하므로 복잡하지만 유연하다. 메모리 조각화를 관리해야 한다.
4. 성장 방향이 다르다
스택과 힙을 반대 방향으로 성장시키면, 메모리 공간을 최대한 활용할 수 있다. Stack Overflow와 Heap Overflow를 독립적으로 감지할 수도 있다.
정리하면, 스택과 힙은 "다른 목적을 가진 다른 메모리"이기 때문에 분리되었다. 하나로 합쳐두면 관리가 복잡해지고 비효율적이다.
"왜 굳이 나누지?"에서 출발했는데, 따져보니 오히려 안 나누는 게 이상한 거였다.
CPU와 I/O의 관계
OSTEP을 읽다가 문득 걸린 부분이 있었다.
"CPU는 I/O 중일 때도 다른 작업을 실행할 수 있다"라고 했다.
그런데 조금 뒤를 읽어보니 I/O가 CPU 작업을 기다리는 상황이 나온다.
잠깐, 동시에 돌아갈 수 있다면서 왜 기다려? CPU 작업 중에 I/O를 하면 안 되는 건가?
이 의문이 한참 머릿속을 맴돌았다.
📌 CPU와 I/O는 동시에 돌아갈 수 있다
먼저 사실 확인부터 했다.
CPU와 I/O 장치는 물리적으로 별개의 하드웨어다. CPU는 연산을 수행하고, 디스크 컨트롤러나 네트워크 카드 같은 I/O 장치는 데이터를 읽고 쓴다.
디스크 컨트롤러가 데이터를 읽는 동안, CPU는 얼마든지 다른 프로세스를 실행할 수 있다.
병렬 실행이 가능하다. 여기까지는 맞다.
📌 그런데 왜 I/O가 CPU를 기다리는 것처럼 보이는가
처음엔 "I/O 장치가 독립적이니까 CPU 작업 중에도 알아서 시작하는 거 아닌가?"라고 생각했다. 근데 한 발짝 더 들어가보니 전혀 아니었다.
I/O를 "시작"하려면 CPU가 반드시 필요하다.
I/O는 마법처럼 저절로 시작되지 않는다.
- 프로세스가 Running 상태여야 한다
- CPU 위에서 시스템 콜을 실행한다
- 커널이 I/O 요청 구조체를 만들고, 장치 레지스터에 명령을 쓰고, DMA를 세팅한다
- 그제서야 I/O 장치가 독립적으로 작동하기 시작한다
I/O 요청 발행 (CPU 필요)
↓
I/O 수행 중 (CPU 불필요 - 장치가 독립 작동)
↓
I/O 완료 처리 (CPU 필요)
CPU 작업만 계속 실행 중이면, I/O 요청을 발행할 기회 자체가 없다. 이게 I/O가 "CPU를 기다리는 것처럼" 보이는 이유였다.
이걸 깨닫고 나니까 바로 비유가 떠올랐다.
🧺 세탁기와 사람
- 사람 = CPU
- 세탁기 = I/O 장치
세탁을 하려면
- 사람이 세탁기 버튼을 눌러야 한다 (CPU 필요)
- 세탁기는 혼자 돌아간다 (CPU 불필요)
- 끝나면 사람이 와서 꺼내야 한다 (CPU 필요)
사람이 계속 다른 일만 하고 버튼을 안 누르면, 세탁기는 "사람 일이 끝날 때까지 기다리는 것처럼" 보인다.
"CPU 작업 중에 I/O를 할 수 없다"가 아니라, "CPU를 잠깐 써서 I/O 요청을 한 번 발행해야, 그 이후에야 I/O가 CPU와 병렬로 돌아간다"가 정확한 표현이다.
처음에 "왜 I/O가 기다리지?"라는 의문에서 출발했는데, 결국 기다리는 게 아니라 시작 자체를 못 한 거였다. 이걸 구분하고 나니 뒤의 스케줄링 정책이 왜 중요한지가 확 와닿았다.
📌 순서가 성능을 결정한다
| 순서 | 결과 |
|---|---|
| CPU 작업을 먼저 몰아서 함 | I/O 시작이 늦어짐 → CPU idle 발생 |
| I/O 요청을 먼저 발행 | I/O 대기 중 CPU 작업 실행 → overlap 발생 |
I/O를 먼저 발행하고, CPU는 다른 일을 한다. 이것이 병렬성을 살리는 핵심이다.
시간 →
P1: [I/O 요청][ BLOCKED ][완료]
P2: [ CPU 작업 실행 ]
↑
P1이 Blocked인 동안 P2가 CPU 사용
동시에 I/O 장치는 P1의 I/O 수행 중
반대로 I/O를 늦게 발행하면?
시간 →
P2: [ CPU 작업 실행 ][DONE]
P1: [I/O 요청][BLOCKED][완료]
↑
CPU가 놀고 있다
P2가 CPU를 점유하는 동안 P1은 I/O 요청조차 못 한다. P2가 끝나고 나서야 P1이 I/O를 시작하면, I/O 수행 중 CPU가 놀게 된다.
좋은 스케줄링 정책은 이 병렬성을 최대한 활용한다.
이론적으로는 이해했는데, 과연 정책 하나로 정말 유의미한 차이가 나는 걸까? 직접 확인해봤다.
정책이 만드는 차이
📌 실험 설계
OSTEP에서 정책 차이만으로 CPU 이용률이 크게 달라진다고 했는데, 솔직히 "진짜 그 정도야?"라는 의심이 들었다.
그래서 OSTEP 공식 시뮬레이터(process-run.py)를 직접 돌려봤다.
이 시뮬레이터는 University of Wisconsin-Madison의 CS-537 강의에서 사용되는 도구로, 프로세스 스케줄링을 간단한 모델로 시뮬레이션한다.
시뮬레이터가 모델링하는 상태
RUN:cpu- 순수 CPU 연산 1 tickRUN:io- I/O 요청 발행 (CPU 1 tick 소모)BLOCKED- I/O 수행 중 (CPU 불필요, 기본 5 tick)RUN:io_done- I/O 완료 처리 (CPU 1 tick 소모)
OS가 선택해야 할 정책은 두 가지다.
- 정책 A: I/O 요청 시 다른 프로세스로 전환할까? (SWITCH_ON_IO vs SWITCH_ON_END)
- 정책 B: I/O 완료 시 해당 프로세스를 즉시 실행할까? (IO_RUN_IMMEDIATE vs IO_RUN_LATER)
📌 실험 1: CPU 프로세스만 2개
가장 단순한 경우부터 시작했다. CPU 작업만 수행하는 프로세스 2개를 동시에 실행한다.
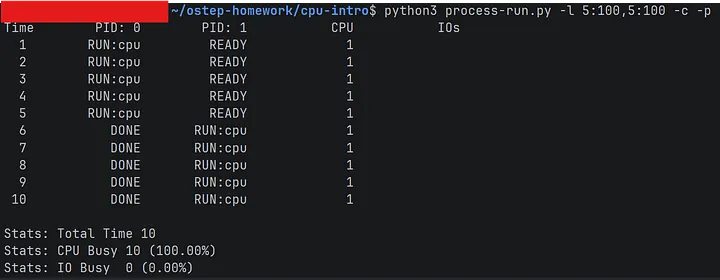
PID 0이 5 tick 동안 CPU를 사용한 후, PID 1이 이어서 5 tick 동안 CPU를 사용한다.
Total Time 10, CPU 이용률 100%.
I/O가 없으니 CPU가 쉴 틈이 없다. 당연한 결과다. 이걸 기준선으로 잡고, I/O가 추가되면 어떻게 달라지는지 살펴봤다.
📌 실험 2: CPU 프로세스 + I/O 프로세스
CPU 프로세스(4 tick)와 I/O 프로세스(1회)를 함께 실행한다.
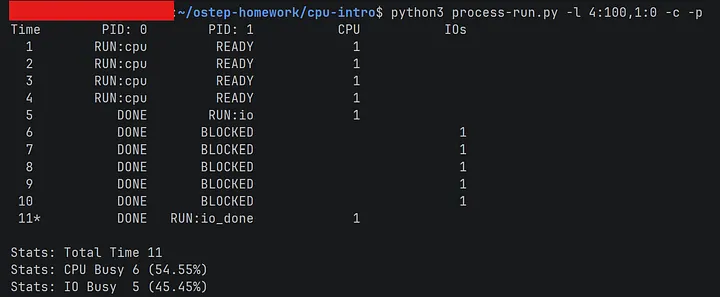
PID 0(CPU)이 4 tick을 모두 사용한 후에야 PID 1(I/O)이 실행된다. PID 1이 I/O를 요청하면 5 tick 동안 BLOCKED 상태가 되는데, 이 동안 CPU가 완전히 놀고 있다.
Total Time 11, CPU 이용률 54.55%.
I/O 프로세스 하나 추가했을 뿐인데 CPU 이용률이 100%에서 54.55%로 떨어졌다. 절반 가까이 날아간 거다.
원인은 명확했다. PID 0이 CPU를 점유하는 동안 PID 1은 I/O 요청조차 발행하지 못한다. 위에서 설명한 세탁기 비유 그대로다. 사람이 버튼을 안 누르고 있으니 세탁기가 멈춰있는 꼴이다.
📌 실험 3: 정책의 차이 - 4개 프로세스
이제 본격적으로 정책의 힘을 확인할 차례다.
I/O 프로세스(3회) 1개와 CPU 프로세스(5 tick) 3개를 동시에 실행한다. 정책만 달리 적용한 두 결과를 비교했다.

🔴 비효율적인 선택: I/O 완료 시 나중에 실행 (IO_RUN_LATER)
PID 0이 I/O를 요청하면 다른 프로세스(PID 1)로 전환하는 것까지는 좋다.
문제는 PID 0의 I/O가 완료된 후다. Time 7에서 RUN:io_done으로 I/O 완료를 처리하지만, PID 0에게 곧장 CPU를 주지 않는다. 대신 PID 2, PID 3의 CPU 작업을 먼저 처리한다.
그 결과, PID 0은 Time 17에서야 다음 I/O를 요청하고, 또다시 BLOCKED된다. PID 0의 세 번째 I/O가 끝나는 것은 Time 31이다.
Total Time 31, CPU 이용률 67.74%.
Time 1923, 2630 구간을 보면 CPU 열에 아무 표시가 없다. CPU가 놀고 있다. 다른 프로세스는 모두 DONE인데, PID 0만 BLOCKED 상태로 I/O 완료를 기다리고 있다.
🟢 효율적인 선택: I/O 완료 시 즉시 실행 (IO_RUN_IMMEDIATE)
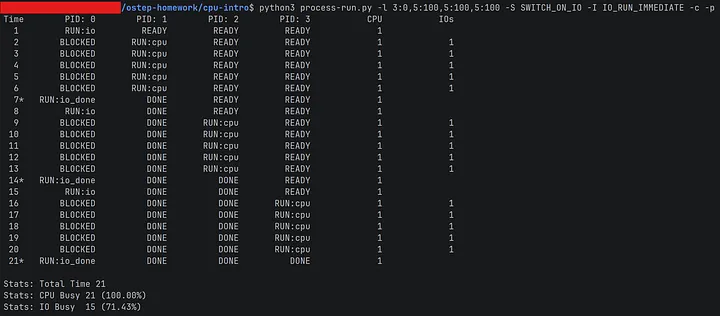
같은 프로세스 조합이다. 바뀐 것은 정책 하나뿐이다.
PID 0의 I/O가 완료되면 즉시 PID 0에게 CPU를 할당한다. PID 0은 io_done 처리 후 곧바로 다음 I/O 요청을 발행하고, 다시 BLOCKED에 진입한다.
이 덕분에 I/O 장치가 쉬지 않는다. PID 0이 BLOCKED인 동안 CPU는 PID 1, 2, 3의 CPU 작업을 처리한다.
Total Time 21, CPU 이용률 100%.
CPU 열에 1이 21 tick 내내 찍혀 있다. CPU가 단 한 순간도 놀지 않았다.
📌 비교 정리
| 정책 | Total Time | CPU 이용률 |
|---|---|---|
| IO_RUN_LATER | 31 | 67.74% |
| IO_RUN_IMMEDIATE | 21 | 100% |
차이: 총 시간 32% 감소, CPU 이용률 32%p 증가.
같은 프로세스, 같은 메커니즘(시분할)인데 정책 플래그 하나만 바꿨을 뿐이다.
솔직히 이 결과를 보고 좀 놀랐다. 물론 단순화된 시뮬레이터라 실제 OS에서 이 정도 차이가 그대로 나타나진 않겠지만, 정책 하나에 의해 CPU idle이 완전히 사라진다는 사실은 인상적이었다.
📌 핵심 통찰
1. 정책은 하드웨어 병렬성을 좌우한다
- 나쁜 정책은 CPU와 I/O 장치 중 하나를 놀게 만든다.
- 좋은 정책은 CPU와 I/O 장치가 동시에 일하게 만든다.
2. 메커니즘과 정책의 분리가 중요한 이유
동일한 시분할 메커니즘 위에서, 정책을 바꾸는 비용은 플래그 하나 수준이다. 성능 개선은 32%p.
정책이 메커니즘에 하드코딩되어 있었다면 이런 유연한 전환은 불가능했을 것이다.
위에서 "메커니즘과 정책이 그게 그거 아닌가?" 싶었다고 했는데, 이 실험 결과를 보고 나서 왜 OSTEP이 이 둘의 분리를 그토록 강조했는지 이해가 됐다.
3. "최선의 정책"은 존재하지 않는다
- 문맥 교환 비용이 크면 "전환하지 않음"이 나을 수도 있다.
- I/O-bound 프로세스가 많으면 "즉시 실행"이 CPU-bound 프로세스를 굶길 수도 있다.
실제 OS는 이런 상황들을 종합적으로 고려한 더 정교한 정책(MLFQ 등)을 사용한다. 이건 이후 챕터에서 더 다뤄볼 생각이다.
Conclusion
📌 프로세스 추상화의 본질
프로세스는 단순한 "실행 중인 프로그램"이 아니다.
OS가 만들어내는 환상이다.
이 환상 덕분에
- 프로그래머는 단순한 코드를 작성할 수 있고,
- 여러 프로그램이 동시에 실행되는 것처럼 보이며,
- 하드웨어 자원을 효율적으로 공유한다.
📌 이 글에서 답한 질문들
- 가상화가 왜 필요한가? → 프로그래밍을 단순하게 만들기 위해
- 시분할이 왜 성능을 낮추는가? → CPU 시간 분할 + 문맥 교환 비용 + 대기 시간
- CPU와 I/O는 왜 함께 일할 수 있는가? → 물리적으로 별개의 하드웨어. 단, I/O 시작/완료에는 CPU가 필요
- 스택과 힙을 왜 나눴는가? → 생명주기, 크기 예측, 관리 방식이 다르기 때문
- 정책이 왜 중요한가? → 같은 메커니즘에서 CPU 이용률이 67%에서 100%까지 차이
처음엔 단순한 개념 정리를 하려고 시작한 글인데, 파고 들어갈수록 "왜?"가 끝없이 이어졌다. 특히 CPU와 I/O 관계에서 **"기다리는 게 아니라 시작을 못 한 거"**라는 걸 깨달은 순간이 이번 챕터에서 가장 큰 수확이었다.
📌 남은 질문들
아직 해결하지 못한 것들
- 문맥 교환 비용은 실제로 얼마나 되는가? → Limited Direct Execution 챕터에서 다룰 예정
- Eager Loading vs Lazy Loading의 세부 동작은? → Paging, Swapping 챕터에서 다룰 예정
- 공정성과 효율성을 어떻게 동시에 달성하는가? → MLFQ, CFS 같은 고급 스케줄러
- 프로세스 간 통신은 어떻게 하는가? → IPC 메커니즘
프로세스 추상화는 OS의 가장 근본적인 추상화다. 이것을 이해하고 나니, 나머지 OS 개념들이 "왜 필요한지" 보이기 시작했다.
Reference
- Remzi H. Arpaci-Dusseau and Andrea C. Arpaci-Dusseau, Operating Systems: Three Easy Pieces (Version 1.10), Arpaci-Dusseau Books, 2023. Chapter 4: "The Abstraction: The Process." https://pages.cs.wisc.edu/~remzi/OSTEP/
- OSTEP Homework - CPU Intro (process-run.py): https://github.com/remzi-arpacidusseau/ostep-homework/tree/master/cpu-intro
- University of Wisconsin-Madison, CS-537: Introduction to Operating Systems: https://pages.cs.wisc.edu/~remzi/Classes/537/Spring2018/
- Abraham Silberschatz, Peter B. Galvin, and Greg Gagne, Operating System Concepts, 10th Edition, Wiley, 2018. Chapter 3: "Processes."